Recette
#1:
Creer une BDD spatiale propre
Février 2011
|
|
Recette
#1: |
|
Février 2011 |
|
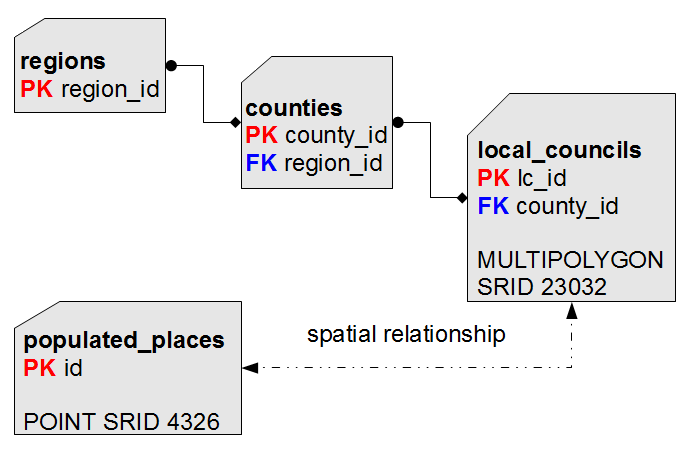
Modèle relationnel Toute base de donnée bien faite est basé sur le modèle
relationnel.
Concernant le jeu de donnée ISTAT Census 2001; identifier les catégories et les relations est très simple:
Ensuite nous avons le jeu de donnée cities1000
: celui ci viens d'une source totalement différente( il n'y a
donc pas d'identifiants permettant d'établir une relation avec
d'autres entités). |
|
CREATE TABLE regions
( |
Étape 1a) on va commencer par créer la table regions
(i.e. 1er niveau hiérarchique).
note: on a définit une
PRIMARY KEY (clé primaire),
i.e. un identifiant unique et non ambigu pour identifier chaque
région.
|
INSERT INTO regions
(region_id, region_name) |
Étape 1b) On va peupler la table regions
.
La requête INSERT INTO
... SELECT ... effectue une copie:
les lignes sont
extraites de la table d'origine, puis insérées dans la table cible.
Comme vous pouvez le constater, les colonnes sont identifiées
dans l'ordre .
|
CREATE TABLE counties
( |
|
INSERT INTO counties
(county_id, county_name, |
Étape 2a) on va maintenant créer et peupler la
table counties.
note: une relation existe entre counties
et regions.
On
va définir une FOREIGN KEY
(clé étrangère) afin d'expliciter cette relation une fois pour
toute.
|
CREATE INDEX
idx_county_region |
Étape 2b) Pour des raisons de performance, on doit créer un INDEX correspondant à chaque FOREIGN KEY que l'on va définir
En faisant simple: une PRIMARY
KEY n'est pas une simple contrainte logique (logical
constraint).
Dans SQLite, définir une PRIMARY
KEY implique la création d'un index implicite supportant
un accès direct rapide à chaque ligne.
En revanche, une FOREIGN
KEY établit simplement une contrainte logique.
Ainsi,
si vous voulez un support rapide à chaque ligne, vous devrez créer
un index spatial.
|
CREATE TABLE
local_councils ( |
|
CREATE INDEX
idx_lc_county |
Étape 3a) On va maintenant créer la table
local_councils.
Une relation liant local_councils
et counties existe
également.
Ainsi, ici aussi, il faudra définir une FOREIGN
KEY , puis créer l'index correspondant.
note:
on a pour l'instant défini aucune colonne géométrique, bien que ce
soit nécessaire pour local_councils;
ce n'est pas une erreur, c'est tout à fait intentionnel.
|
SELECT
AddGeometryColumn( |
Étape 3b) créer une colonne Géométrique nécessite une
procédure particulière.
On doit utiliser la fonction spatiale
AddGeometryColumn(),
en spécifiant:
nom de la table
nom de la colonne geometry
le SRID
le type de géométrie
la dimension
(dans notre cas, 2D simple )
|
INSERT INTO
local_councils (lc_id, |
Étape 3c) Enfin, nous pouvons peupler la table local_councils comme d'habitude.
|
CREATE TABLE
populated_places ( |
|
SELECT
AddGeometryColumn( |
|
INSERT INTO
populated_places (id, |
Étape 4) Dernière étape: créer (et peupler) la table
populated_places.
Plusieurs points importants ici:
on a utilisé la clause AUTOINCREMENT pour PRIMARY KEY
ceci signifie que SQLite générer automatiquement un ID unique approprié pour cette PRIMARY KEY lorsque aucune valeur n'a été spécifiée.
d'après tout ceci, après INSERT
INTO la valeur NULL
a été explicitée pour peupler la PRIMARY
KEY:
ceci indique explicitement à SQLite de remplir
automatiquement ce champ.
le jeu de donnée original
cities1000
contient deux colonnes longitude [COL006]
et latitude [COL005]:
on a donc utilisé la fonction spatiale MakePoint()
afin de créer une géométrie de type POINT.
en spécifiant le SRID 4326 on instancie la géométrie avec le SRS WGS84 [Geographic System].
|
Récapitulatif rapide:
|
|
DROP TABLE
com2001_s; |
Étape 5) Finalement vous pouvez
supprimer les Virtual Tables, nous ne les utiliserons
plus.
Note: le fait de supprimer les tables virtuelles ne
supprime en aucun cas les fichiers sources, mais juste le lien entre
ces fichiers et votre BDD
|
|
Author: Alessandro Furieri a.furieri@lqt.it |
|
This work is licensed under the Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0) license. |
|
|
|
|
|
|
Permission is granted to copy, distribute and/or modify this
document under the terms of the |