Back to dataSeltzer documentation index
Selecting and querying a dataset
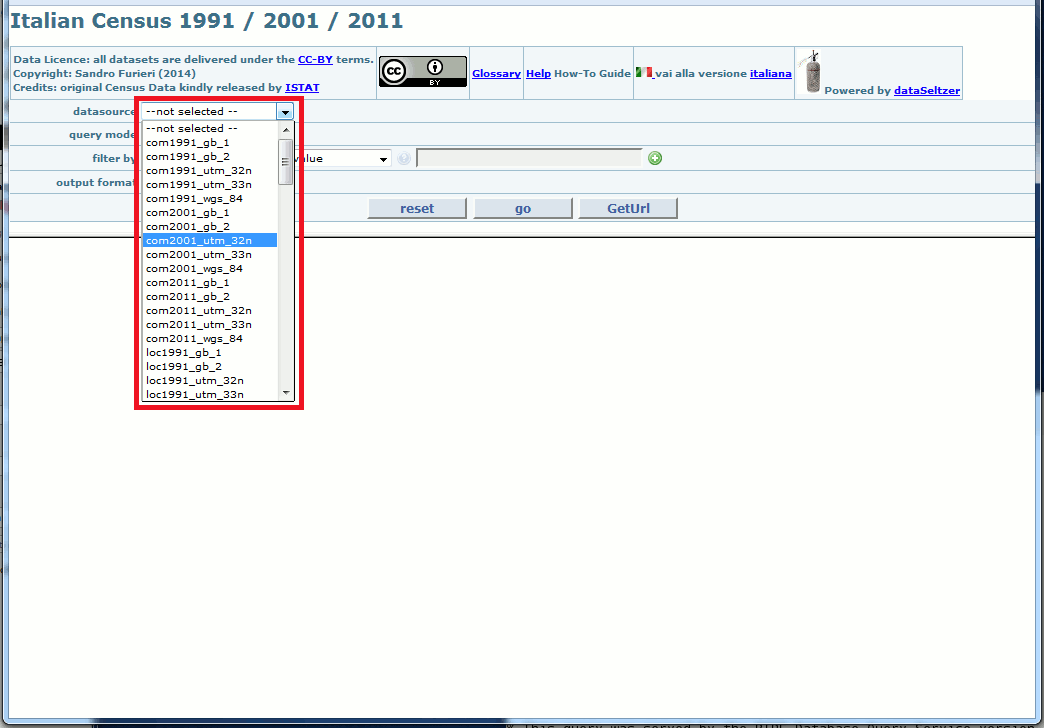
dataSeltzer could usually publish more that a single a dataset/datasource: so the first step always is choosing a specific dataset of your interest.
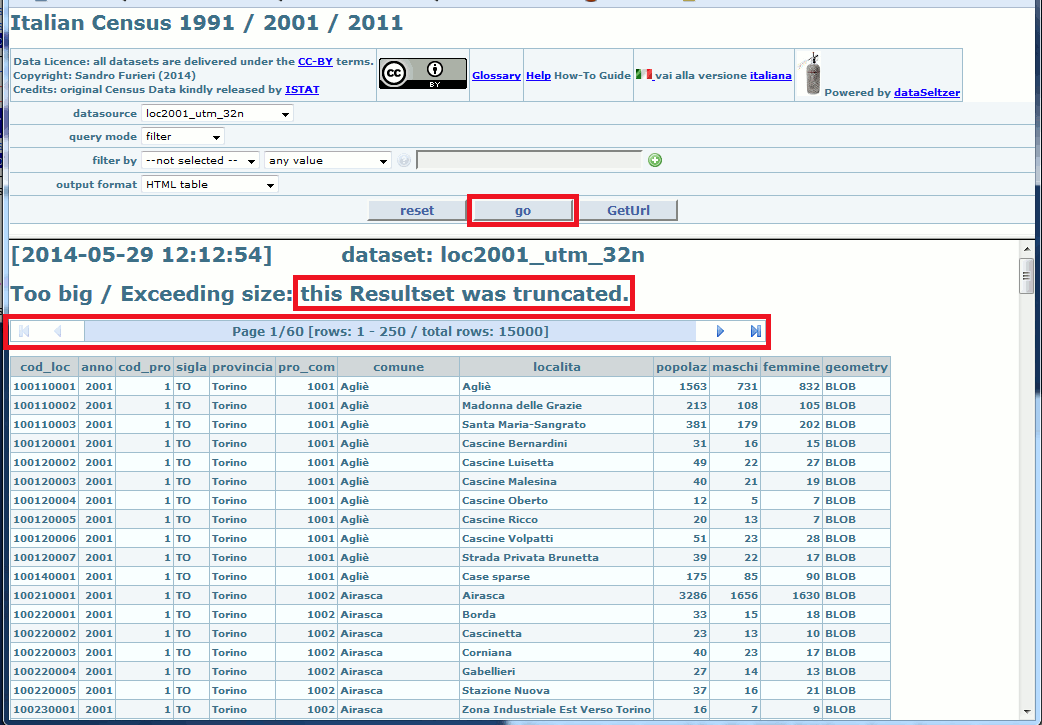
In this first example we'll directly query the whole dataset without applying any filter. Just click the go button, and the resultset will be immediately printed on the screen.
For efficiency reasons only a limited number of rows from the resultset will be printed at each time. Anyway you can easily explore all resultset pages; you simply have to click the navigation links first page, last page, previous page and next page.
Please note: anyway querying an huge dataset containing many rows without applying any filter could be a very lengthy and time consuming operation; and the WebAdmin could had eventually applied some automatic truncation criteria imposing an upper limit to the number of rows returned by a single query.
If this this is your actual case, you'll be warned by an explicit message that truncation actually happened. Repeating yet another time your query by applying a more selective filter is the most obvious solution.
Applying filters to your queries
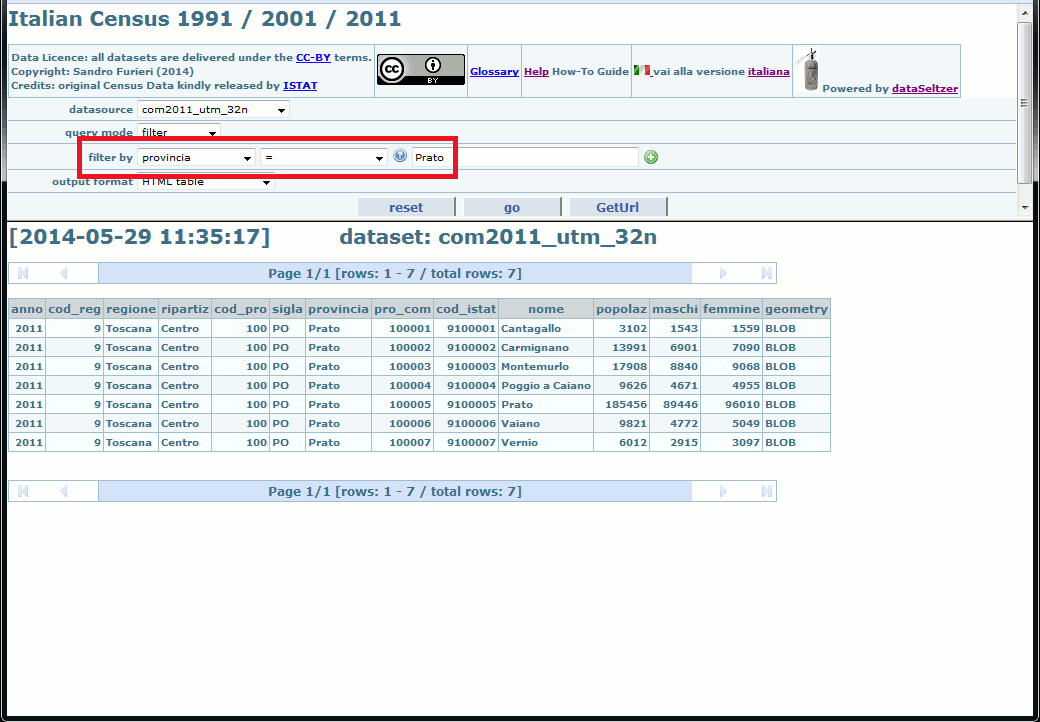
A filter effectively allows to selectively restrict the returned rows by applying some comparison criteria; only the rows positively matching that criteria will be inserted into the resultset. e.g. in this query we've imposed a filter selecting only the Local Councils belonging to the Province of Prato.
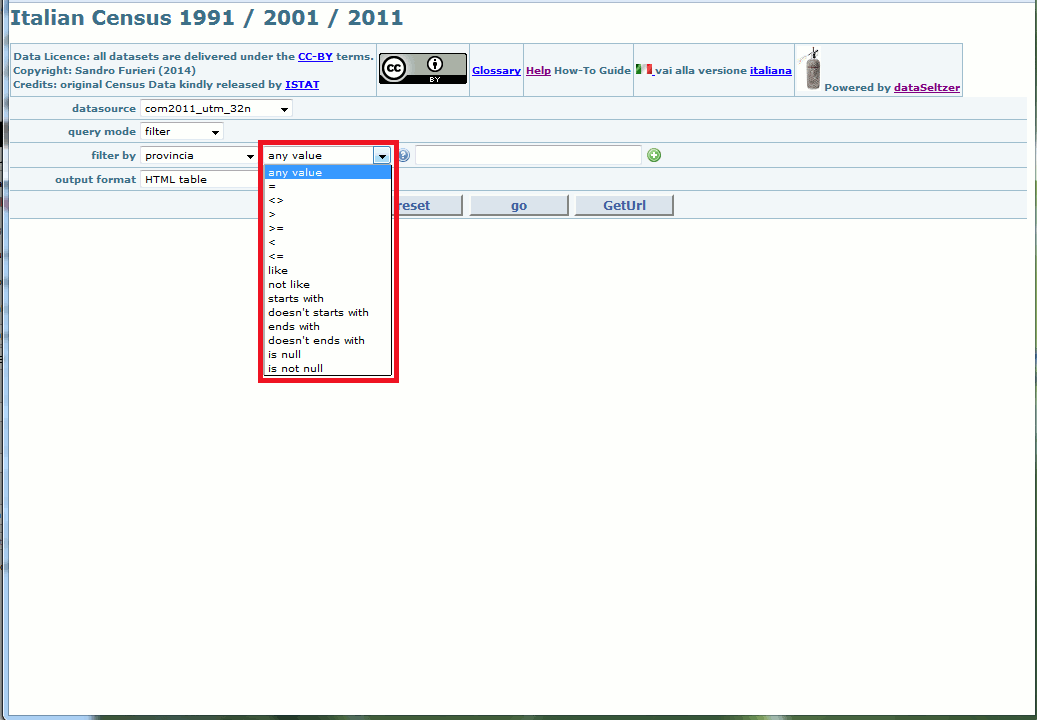
You can freely choose between several different comparison operators.
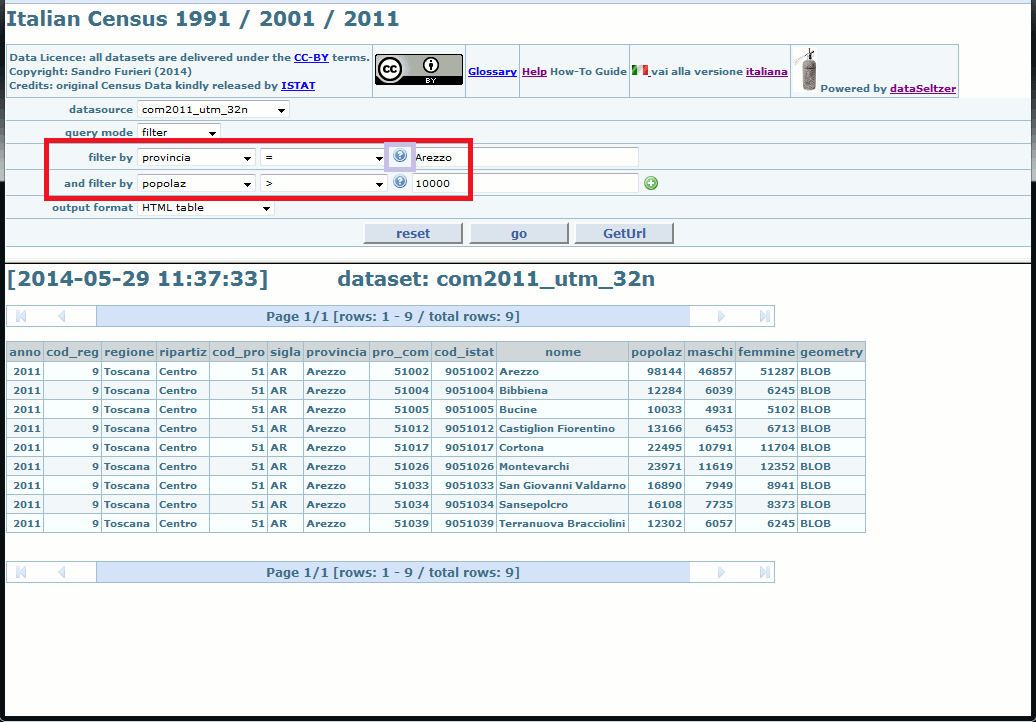
And you can eventually apply more filters at the same time: only the rows satisfying all filters will be inserted into the resultset.
Please note: you can add an arbitrary number of filters; just click the add button to add one more filter.
Selecting the any value comparison operator, or missing to specify a corresponding value to be compared disables the filters, which in this case will simply be ignored.
You can eventually click the help button in order to get a list of meaningful values to be used in some comparison.
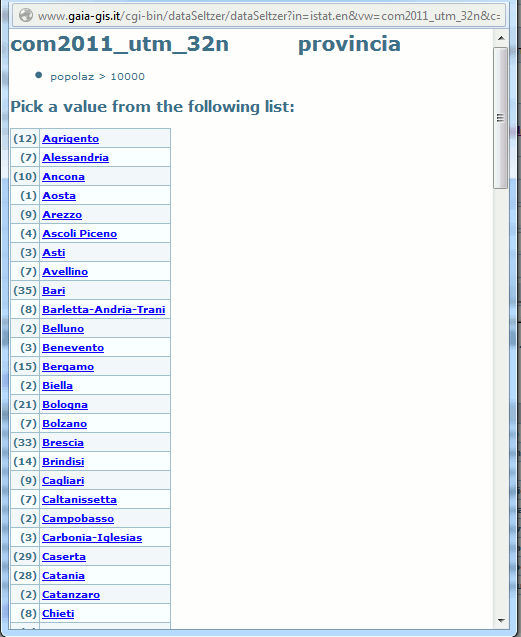
When you press the help button a floating window will appear showing the list of unique values corresponding to the currently selected column.
You simply have to click one of the items and the corresponding value will be automatically copied into the appropriate field of the main WEB page.
Caveat: even the help list of unique values could be eventually subject to truncation, if some upper limit was imposed by the WebAdmin.
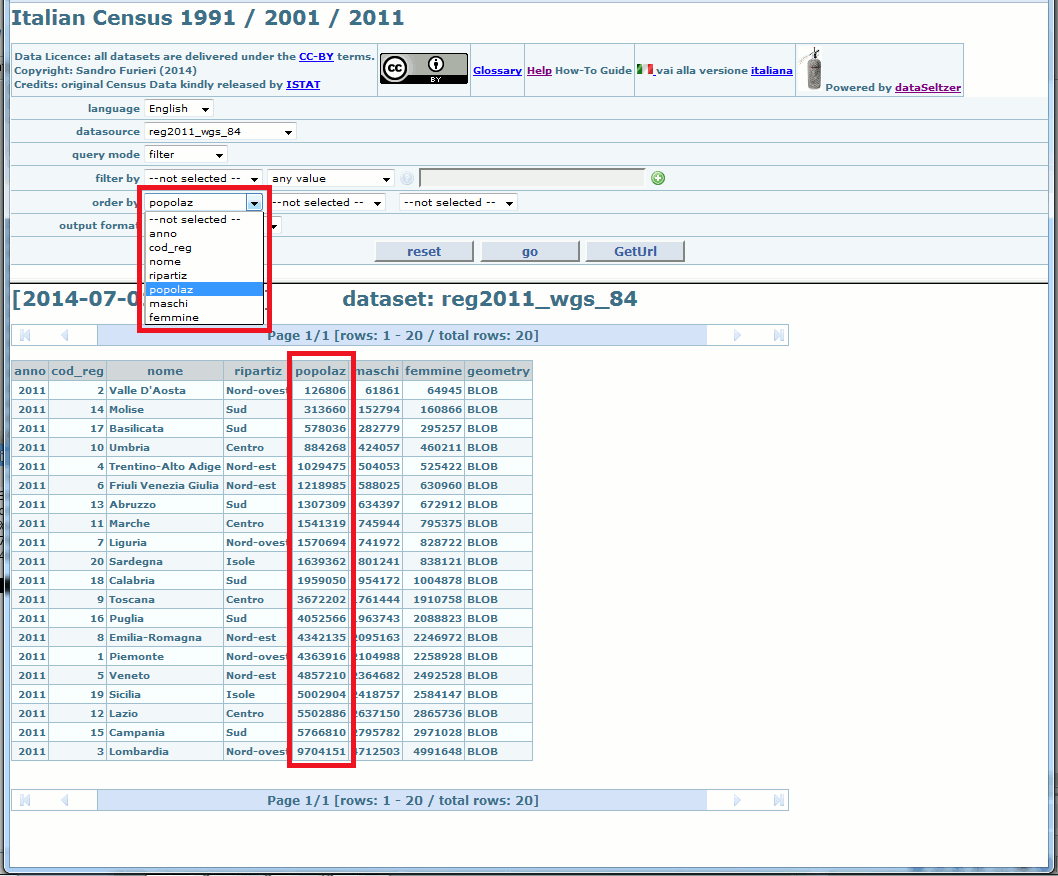
Finally you could wish to explicitly request to order the extracted rows accordingly to some criteria; in this case you simply have to select the appropriate column(s).
Downloading a dataset
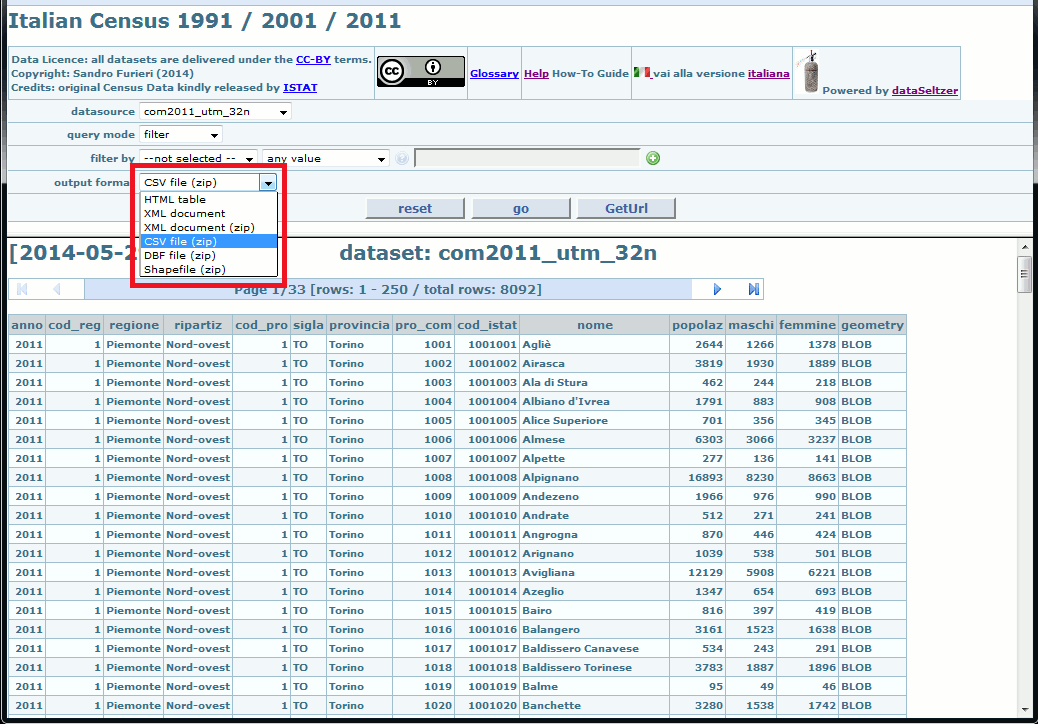
Once you've applied a satisfying set of filters and after verifying that the resultset exactly corresponds to your requirements, you can eventually download the resultset in one of the following standard formats:
- XML: an universal standard format
- XML-zip: same as above. But in this case you'll effectively download a Zipfile containing the XML document instead of directly receiving a text/xml payload.
- CSV: another standard format usually accepted by many spreadsheet applications.
- DBF: an alternative standard format usually accepted by many spreadsheet apps.
- only in the case when the resultset does contain some Geometry it could eventually exported as a Shapefile, a common standard format supported by many GIS apps.
- and finally you could eventually directly download a SQLite / SpatiaLite DB-file containing the extracted dataset.
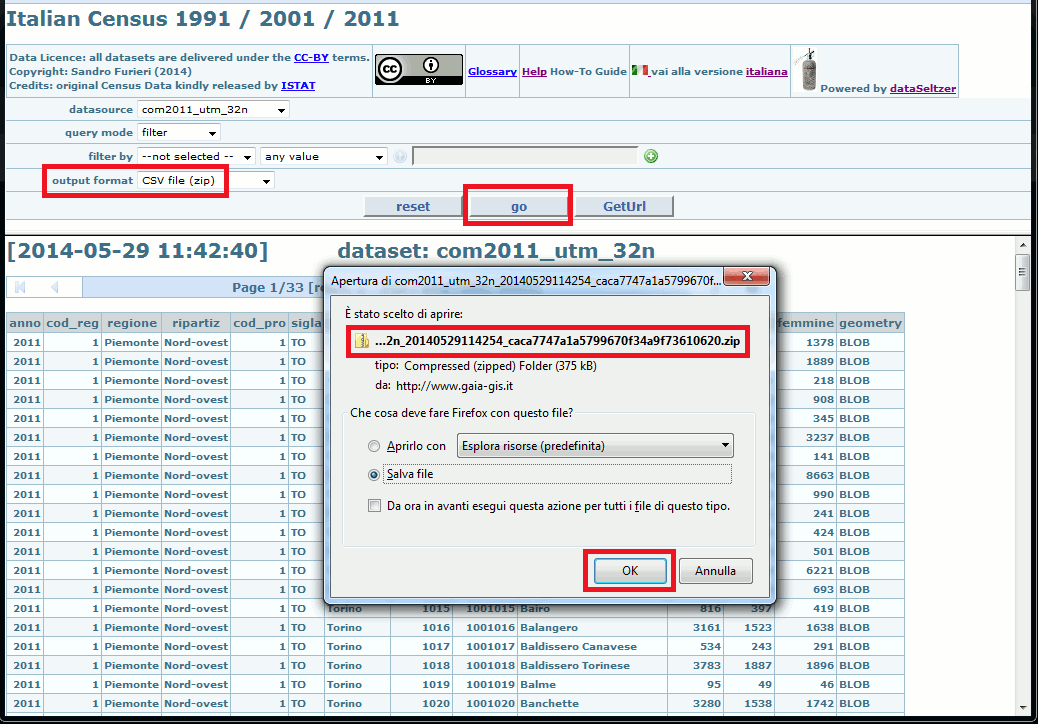
Just select the export format of your choice, then press the go button; and the download will immediately start.
Every downloaded dataset will consist in a compressed ZipFile presenting a name of the following form:
dataset_20140427120853_9ab9dda606518d15996a89f6b20bdc64.zip
- the first part exactly corresponds to the name of the dataset/datasource.
- the second part corresponds to the current timestamp formatted as YYYYMMDDHHmmSS
- the final part represents the MD5 checksum as computed on the zipfile itself.
Aggregate queries
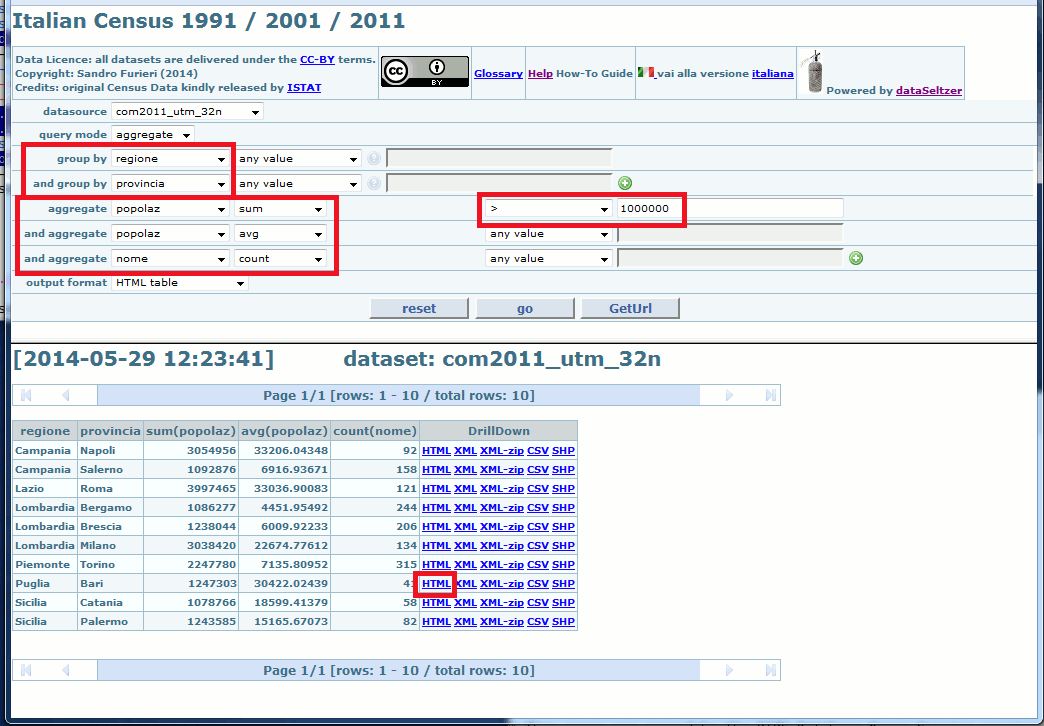
dataSeltzer supports a second kind of queries; using an aggregate query you'll not get every single row from the input dataset (as in a plain query).
You'll get instead a single row for every packet of similar rows aggregated by some criteria, and you can eventually perform some useful computation on behalf of each aggregate/packet.
In this first example we'll use a Local Councils sample dataset:
- all Local Councils will be grouped by Region and Province.
- and for each Province the following values will then be computed:
- the total population (year 2011), as the sum of all aggregate Local Councils populations.
- the average population for each Local Council in that Province (avg).
- the total count of Local Councils belonging to that Province (count).
- finally, we've imposed a filter requesting that only Provinces having a total population exceeding 1 million will be included into the resultset: sum(popolaz) > 1000000
An aggregate query supports a further interesting feature: you could eventually use one of the DrillDown hyperlinks in order to explore / explode all individual rows being grouped within the same aggregate packet.
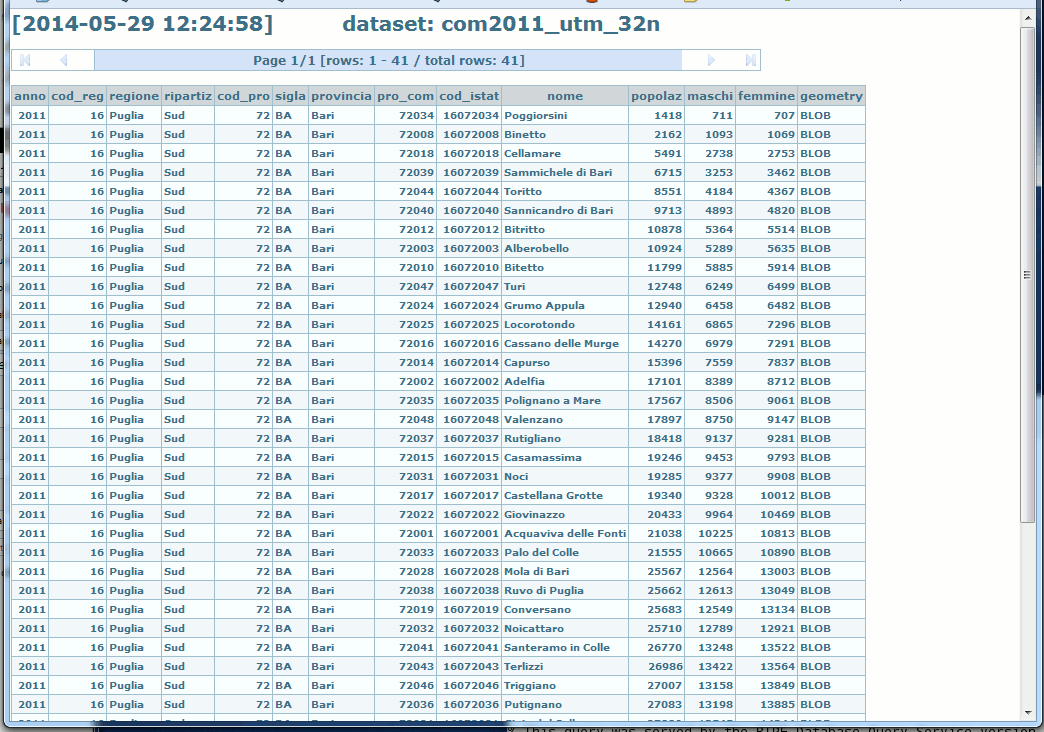
e.g. in this case dataSelzer will open a new HTML tab showing all Local Councils being grouped so to build the Province of Bari aggregate packet.
the GetUrl feature
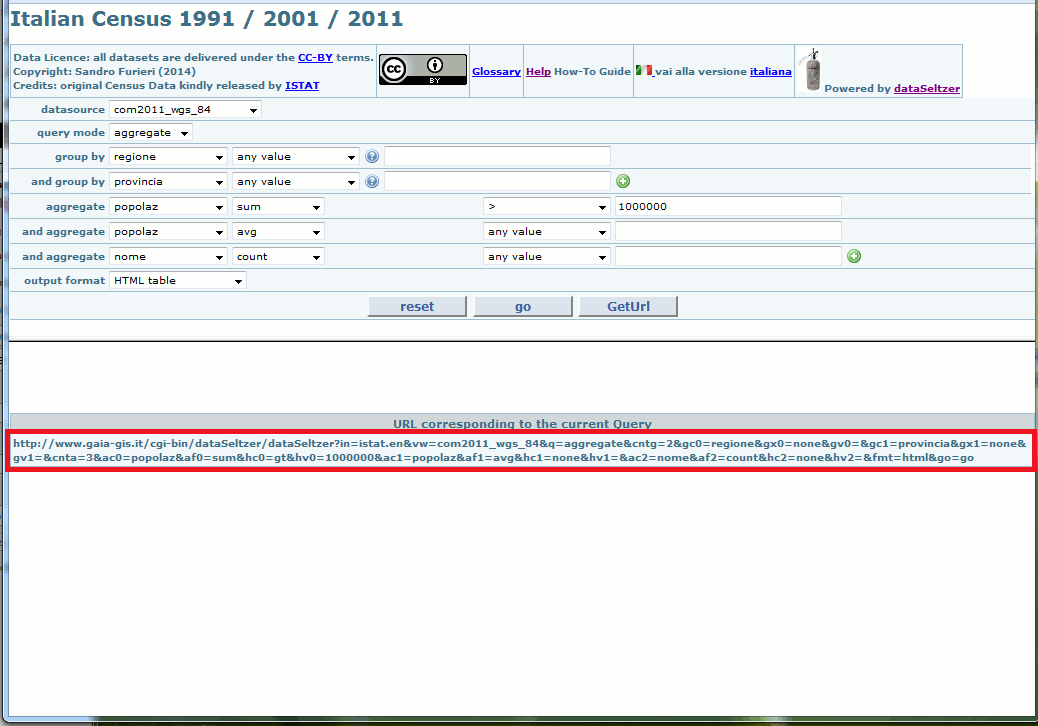
By clicking the GetUrl button the full request URL (method GET) exactly corresponding to the current query will be shown.
This one is an useful option, because this way you can easily include a download service based on dataSeltzer on a different WEB page, thus further extending the usability of dataSeltzer-based services.
the hidden select argument
An extra argument exists: it's never directly accessible from the User Interface, but you could eventually manually add it to your request URLs of the filtered type (it's fully supported by the CGI component).Just a quick explanation:
- usually any request URL will be internally translated into an appropriate SQL query; and such query will always be of the generic form:
- SELECT * FROM ....
- if any &select=string is specified within the request URL, then string will be assumed to identify the requested columns, and will thus replace thegeneric * wild-card.
http://www.gaia-gis.it/cgi-bin/dataSeltzer?in=istat.it&vw=com2001_wgs_84&q=filter&cnt=1&c0=regione&x0=eq&v0=Toscana&fmt=html&go=go&select=regione,provincia,nome,popolazthis first request URL will just return the regione, provincia, nome and popolaz columns exactly in this order.
http://www.gaia-gis.it/cgi-bin/dataSeltzer?in=istat.it&vw=com2001_wgs_84&q=filter&cnt=1&c0=regione&x0=eq&v0=Toscana&fmt=html&go=go&select=nome%20as%20comune,%20popolaz%20as%20%22pop_2011%22,%20femmine%20-%20maschi%20AS%20diff_m_f,%20provincia,%20regionethis second examples shows how you could eventually alter the relative column order, change the column names and eventually computing some expression.
http://www.gaia-gis.it/cgi-bin/dataSeltzer?in=istat.it&vw=com2001_wgs_84&q=filter&cnt=1&c0=regione&x0=eq&v0=Toscana&fmt=html&go=go&select=invalid-sql-syntaxIf for any reason the &select=string do actually correspond to some invalid SQL syntax then an empty dataset will be returned.
Back to dataSeltzer documentation index
|
Credits Development of dataSeltzer has been funded by Tuscany Region - Territorial and Environmental Information System Regione Toscana - Settore Sistema Informativo Territoriale ed Ambientale. |