Back to dataSeltzer documentation index
Building the dataSeltzer CGI
dataSeltzer is an elementary simple component, so building it starting directly from the source distribution isn't expected to be a difficult task by itself.You are simply required to follow the usual canonical way:
./configure makePlease note: correctly determining the libspatialite own configuration requires using pkg-config (check that you've already installed the appropriate system package before attempting to configure your custom build).
On some Linux distributions (e.g. on CentOS and Fedora) if you are using a custom-built libspatialite you'll probably be required to explicitly set an extra environment variable; so your build should look something like this:
export "PKG_CONFIG_PATH=/usr/local/lib/pkgcofig" ./configure make
Required dependencies
dataSeltzer strictly requires these dependencies to be satisfied at build time:- libspatialite: dataSeltzer doesn't supports sophisticated Spatial Queries, just a minimalistic bare supported is expected in order to correctly create all Shapefiles and DBF datasets to be exported. So you could probably successfully try using some obsolete libspatialite system package; or alternatively you could consider as an emergency solution to build from sources a severely gilded libspatialite by disabling any support for Proj.4, GEOS, liblwgeom and/or libxml2.
- libexpat: this small XML-parsing library is required in order to parse the configuration file required by dataSeltzer; this library is usually shipped as a system package on every Linux distribution, so shouldn't pose any issue (anyway carefully check if the appropriate -devel package is already installed on your system).
- libcgi: this CGI-support library is widely distributed, but it's not a standard system package on several Linux distros (e.g. it's unsupported on CentOS 6.5, as I sadly learned by direct experience).
- If this is your case, you can reasonably perform a custom build on your own directly starting from the sources: libcgi-1.0.tar.gz
You should simply follow the usual canonical approach:./configure make sudo make install
Anyway this simplistic approach failed on my CentOS 6.5, and I got a fatal error concerning the impossibility to build a shared object due to a missing -fPIC declaration forbidding to compile relocatable binary code. I've simply by-passed this issue this way:export "CFLAGS=-fPIC" ./configure make sudo make install
- If this is your case, you can reasonably perform a custom build on your own directly starting from the sources: libcgi-1.0.tar.gz
- libminizip: this library supports creating ZipFiles on Linux systems; it's currently shipped as a standard system package on Fedora, but not on many other distributions (e.g. it's not available on CentOS 6.5).
- If this is your case, you can anyway perform a custom build on your own directly starting from the sources that are included in every standard distribution of the popular libz; just go to the contrib/minizip directory. The zlib more recent sources are available from here: zlib-1.2.8.tar.gz
Building libminizip is a little bit trickier than usually expected, because just a bare configure.ac is supplied but no standard ./configure is make directly available.
So you should execute all the following commands in order to successfully build and install libminizip:cd zlib-1.2.8/contrib/minizip aclocal automake --add-missing autoconf libtoolize ./configure make sudo make install
- If this is your case, you can anyway perform a custom build on your own directly starting from the sources that are included in every standard distribution of the popular libz; just go to the contrib/minizip directory. The zlib more recent sources are available from here: zlib-1.2.8.tar.gz
Testing a custom built dataSeltzer CGI
After performing a custom build carefully testing the binary code always is a suggested good practice; and this is even more advisable in the case of a CGI component intended to be deployed in a security sensible Web environment. You can test the dataSeltzer CGI following two consecutive steps:make distclean export "CFLAGS=-O0 -g" ./configure --enable-gcov=yes make make coverage-init make check make coverageIf anything runs smoothly you can go to the covresults directory then opening index.html using any Web Browser; and you'll be able to examine the code coverage analysis results.
The second diagnostic step implies using Valgrind, a well known dynamic code analysis tool supporting a thorough and comprehensive memory check intended to identify any possible memory leak, buffer overflow, memory corruption and alike (thus potentially preventing many unpleasant crashes in a sensible production environment).
cd tests sh test_under_valgrind.sh 2>report vi report
how the test coverage works - internal details
Testing a CGI component is a little bit more complex than testing an ordinary program, because a CGI component is not intended to be directly executed outside a Web Server context.If you notice, you'll find a tests/pseudo_url.tests file included within the standard source distribution; this file contains about 140 different pseudo-request-URLs, and the test/test_cgi program will check all them by repeating invoking the CGI component, thus effectively simulating the working environment of a real Web Server but effectively avoiding any network access.
And test/test_cgi will automatically update the tests/test_under_valgrind.sh script; so if you wish to add more tests you are simply required to add more pseudo-URLs into the tests/pseudo_url.tests file, then executing tests/test_cgi and finally launching the Valgrind script.
Installing the dataSeltzer CGI
For rather obvious security reasons, a Web Server will never attempt to directly execute any binary code coming from the standard directories such as /bin, /usr/bin or /usr/local/bin. So in the specific case of a CGI component the standard make install is intrinsically meaningless; you necessarily have to manually install all CGI-related files in the appropriate locations.
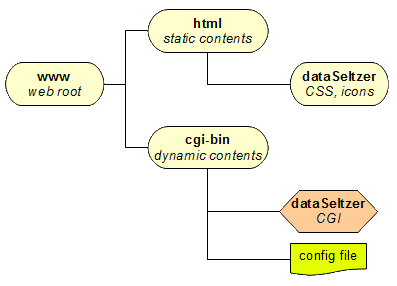 |
Quite almost Web Server have an intentionally restricted visibility just allowing to access a well confined portion of the overall file-system: a commonly found layout (e.g. the one usually adopted by Apache) is the one to designate a main www directory acting as the Web publishing root (actual paths may vary in different distributions). The Web Server (and related children processes, as CGI components) will usually be forbidden to access any other portion of the file-system located outside such Web Root. Usually the Web Root has (at least) two further sub-directories, one (html) intended to contain any static content, and the other (cgi-bin) intended to contain CGI executables supporting dynamic contents creation. dataSeltzer is a CGI, and thus should be installed on cgi-bin; but dataSeltzer also requires accessing few auxiliary static Web contents (icons and CSS stylesheets), and these latter should be installed instead on html. A really good idea could be the one to create a www/html/dataSeltzer sub-directory so to get a properly ordered disk layout. Please note well: the dataSeltzer CGI component strictly requires reading a main configuration file located on the same directory where the CGI itself is. This configuration file is always expected to be named exactly as dataSeltzerMain.conf If such config-file doesn't exist, or isn't readable due to forbidden access permission, then dataSeltzer CGI will be completely unable to correctly operate. |
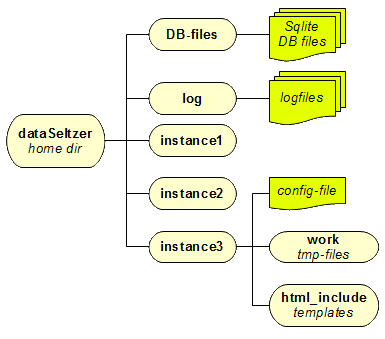 |
A slightly more complex work is correctly configuring the data-directories required by dataSeltzer:
In this example we'll assume a separate home-data-dir so to keep a properly ordered layout:
So a really good idea could be the one to assign to the apache user the ownership of all files and directories intended to be directly read or written by the CGI component. Ensuring that the apache user will effectively have unrestricted access permissions on the work and log directories is strictly required. |
Configuring and Customizing your dataSeltzer Web site
You could eventually quickly setting-up a dataSeltzer test by using the sample config-files (and related stuff) you'll find on the standard source distribution (look at the resources dir).You could eventually use the small DB sample included in the standard dataSeltzer source distribution for your firsts preliminary tests; you'll find this sample on tests/dataSeltzer-minitest.sqlite
Anyway, even after completing all the above steps the dataSeltzer CGI would probably be still unable to correctly start until you complete the following tasks:
- Edit the dataSeltzerMain.conf and dataSeltzer.conf files by carefully checking that all URLs and paths do actually correspond to your local configuration.
- Quickly inspect all HTML templates checking that all URLs do actually correspond to your local configuration.
- Carefully check that the apache user could effectively access all intended files and directories.
- Once you've completed all these very basic steps you should be able to effectively test the CGI component. Just start a Web Browser and go to this URL:
http://www.myserver.com/cgi-bin/dataSeltzer/dataSeltzer - If you encounter some trouble inspecting the standard Apache logfiles access_log and error_log could eventually point your attention in the right direction.
And in this case selecting HTTP GET mode will probably lead to an easier debugging session.
We'll now conclude this short tutorial by examining two special cases worth to be remarked before attempting to configure your own dataSelter.
The intended scope of HTML templates
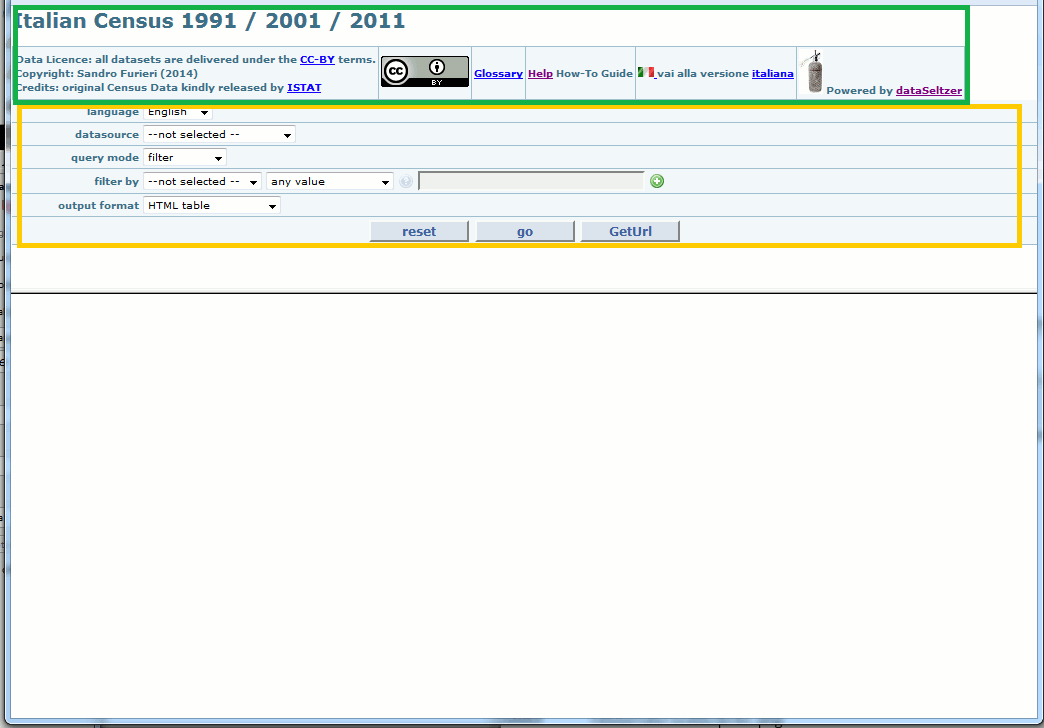
HTML templates simply are static fragments of HTML code intended to be included exactly as they are within some more complex HTML page dynamically created by the CGI component. This nicely allows to freely extend in many ways the rigid internal logic adopted by the CGI component.
Carefully look at the above HTML sample:
- any element within the orange box is dynamically created by the CGI component; you can simply act on CSS styles and / or config-file options so to (marginally) modify the internal logic adopted by the CGI component.
- on the other hand the green box corresponds to an HTML template; you are absolutely free to change this HTML snippet as you wish better.
Handling multiples Instances
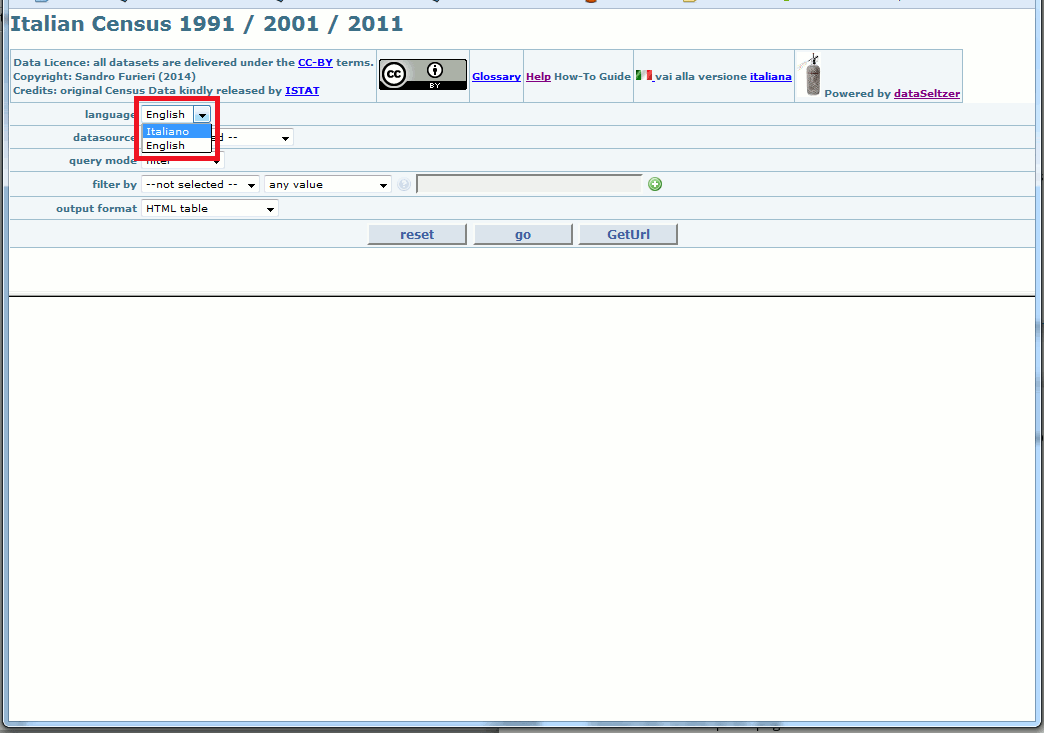
dataSeltzer has the intrinsic capability to service multiple Instances; each single Instance has its own individual config-file, and consequently every Instance is absolutely free to adopt a different styling layout of its own. Usually separate Instances are intended to service different databases, but nothing forbids to deploy two different Instances sharing the same database (e.g. as in this example so to support different national languages).
At least one Instance is expected to be defined, but there is no upper limit; you are free to configure as many Instances as required.
Please, always remember the following basic rules about Instances:
- Each single Instance is uniquely identified by a name and by an human readable title.
- The request URL for each Instance has the following canonical form:
https//www.my-server.com/cgi-bin/dataSeltzer?in=name - If no explicit in=name argument is specified within a request URL then the following convention applies:
- if multiple Instances are defined, then the first one will always be assumed to be the default Instance.
- Corollary: if just a single Instance is defined it will always be implicitly assumed as the target Instance.
- the <EnableMultiInstances> config-option plays a special role:
- if enabled the user will always be able to freely navigate between all published Instances (a further ComboBox will be inserted allowing to choose the intended target Instance - please see the above figure).
- if disabled then a much more strict confinement will be applied; in this case switching to a different Instance will always require explicitly passing a different request URL.
Back to dataSeltzer documentation index
|
Credits Development of dataSeltzer has been funded by Tuscany Region - Territorial and Environmental Information System Regione Toscana - Settore Sistema Informativo Territoriale ed Ambientale. |